Wat is Machine Learning?


Wil jij meer te weten komen over machine learning? Wat het is en hoe je het kunt toepassen in je bedrijf? De problemen die je kunt oplossen en welke modellen en algoritmen je daarvoor moet gebruiken? Dan ben je hier op de juiste plek. Zelfs als je nog nooit van machine learning hebt gehoord!
Wat is Machine Learning
Definitie van Machine Learning
Machine Learning is een vorm van kunstmatige intelligentie (AI) die zich hoofdzakelijk richt op leren van ervaring en het maken van voorspellingen.
Machine learning maakt het mogelijk dat systemen data-gestuurde beslissingen nemen, in plaats van dat ze expliciet worden geprogrammeerd voor een specifieke taak. Deze programma’s of algoritmen zijn ontworpen om te leren van historische data die we ze voeden tijdens het trainingsproces. Tijdens dit proces geven we aan het systeem of de output correct is. Het systeem neemt deze feedback op en corrigeert zichzelf op basis daarvan.
Dit blijft het doen totdat het in de meeste gevallen de juiste output geeft. Uiteraard wordt het niet 100% correct, maar het wordt zo nauwkeurig mogelijk!
Dus Machine Learning zorgt ervoor dat een systeem zelf denkt en keuzes maakt. Mits het voldoende, juiste data heeft kan het leren hoe het deze data moet interpreteren, verwerken en analyseren door de zogenaamde Machine Learning algoritmen. Hierdoor kan het daadwerkelijke bedrijfsproblemen oplossen
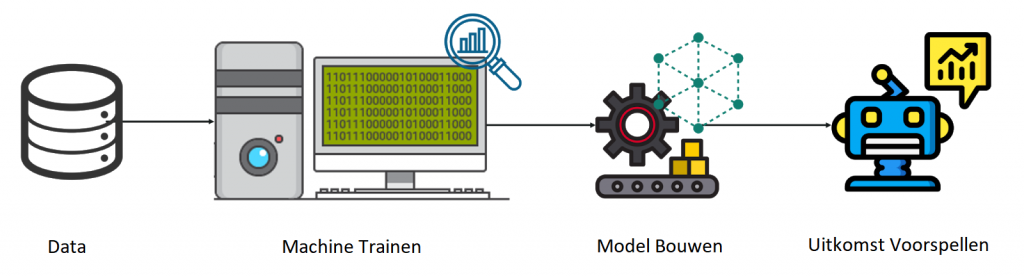
Figuur 1: Definitie van Machine Learning
Termen binnen Machine Learning
Laten we, voordat we verder gaan, enkele van de meest gebruikte termen binnen Machine Learning bespreken:
Algoritme: een machine learning-algoritme is een set regels en statistische technieken die worden gebruikt om patronen uit gegevens/data te leren en er belangrijke informatie uit te halen. Het is de logica achter een Machine Learning-model. Een voorbeeld van een Machine Learning-algoritme is het Linear Regression-algoritme.
Model: een model is het hoofdbestanddeel van Machine Learning. Een model wordt getraind met behulp van een Machine Learning Algorithm. Een algoritme brengt alle beslissingen in kaart die een model moet nemen op basis van de gegeven invoer, om de juiste uitvoer te krijgen.
Voorspellende variabele: het is een functie van de data, die kan worden gebruikt om de ‘output’ (lees: uitkomst) te voorspellen.
Responsvariabele: Met behulp van het bovengenoemde voorspellende variabelen, wordt de functie van de ‘output variabele’ voorspeld.
Trainingsgegevens: het Machine Learning-model is gebouwd met behulp van de trainingsdata. De trainingsdata helpen het model om belangrijke trends en patronen te identificeren die essentieel zijn om de output te voorspellen.
Testgegevens: nadat het model is getraind, moet het worden getest om te evalueren hoe nauwkeurig het een uitkomst kan voorspellen. Dit wordt gedaan door de testdata set.
Waarom is er behoefte Machine Learning?
Sinds de technische revolutie genereren we een onvoorstelbare hoeveelheid data. Per onderzoek genereren we elke dag ongeveer 2,5 biljoen bytes aan data! Geschat wordt dat tegen 2020 voor ieder persoon op aarde 1,7 MB per seconde aan data zal worden aangemaakt.
Met zoveel data beschikbaar, is het mogelijk om voorspellende modellen te bouwen die complexe gegevens kunnen bestuderen en analyseren om nuttige inzichten te vinden en nauwkeurigere resultaten te leveren.
Top bedrijven zoals Netflix en Amazon bouwen dergelijke Machine Learning-modellen door ontzettend veel data te gebruiken om winstgevende kansen te identificeren en ongewenste risico’s te voorkomen.
Hier is een lijst met redenen waarom machine learning zo belangrijk is:
- Toename van data: vanwege de grote hoeveel productie van data, hebben we een methode nodig die kan worden gebruikt om gegevens te structureren, te analyseren en te gebruiken. Dit is waar Machine Learning van pas komt. Het gebruikt gegevens om problemen op te lossen en oplossingen te vinden voor de meest complexe taken waarmee organisaties worden geconfronteerd.
- ‘Decision making’ verbeteren: door gebruik te maken van verschillende algoritmen kan Machine Learning worden gebruikt om betere zakelijk beslissingen te nemen. Machine Learning wordt gebruik om bijvoorbeeld omzet te voorspellen, ondergangen op de aandelenmarkt te voorspellen, risico’s en afwijkingen te identificeren enz.
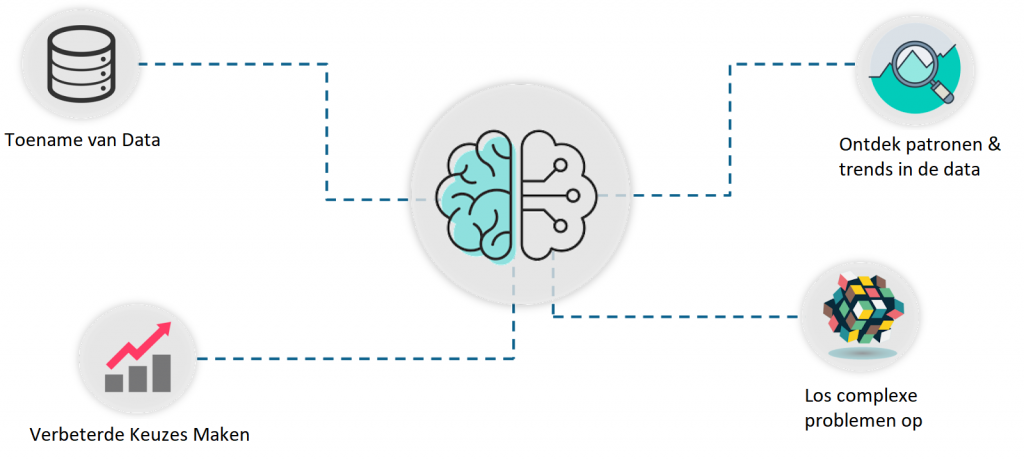
Figuur 2: Waarom machine learning?
- Ontdek patronen en trends in data: Het achterhalen van verborgen patronen en het vergaren van belangrijke inzichten uit gegevens is het meest essentiële onderdeel van Machine Learning. Door voorspellende modellen te bouwen en statische technieken te gebruiken, kan je met Machine Learning onder de oppervlakte graven en de data op een kleine schaal verkennen. Data begrijpen en patronen handmatig extraheren duurt dagen. Terwijl Machine Learning-algoritmen dergelijke berekeningen in minder dan een seconde kunnen uitvoeren.
- Complexe problemen oplossen: Van het analyseren van beelden of bloedmonsters, zodat ziektes sneller worden herkend tot het bouwen van zelfrijdende auto’s, Machine Learning kan worden gebruikt om de meeste complexe problemen op te lossen.
Voorbeelden van Machine Learning
Machine Learning wordt in verschillende industrieën gebruikt om problemen op te lossen. Denk aan Supply chain management, Transport & Planning en de zorg.
Met Machine Learning kan je bijvoorbeeld accurater veranderende vraag voorspellen op basis van een gigantische hoeveelheid data die een menselijke werknemer nooit op tijd zou kunnen doorspitten.
In de transport & planning industrie kan machine learning data analyseren, patronen ontdekken en zo de efficiëntste routes vinden. Maar ook in de zorg is Machine Learning de perfecte aanvulling op vrijwel alle medtech en eHealth-software. Door grote hoeveelheden data te analyseren en te interpreteren, kunnen diagnoses bovendien worden gestaafd en vergeleken, met een completere en beter uitgewerkte diagnose als resultaat.
Verschil tussen AI en Machine Learning
… Laten we verder gaan in Machine Learning door één van de grootste misconcepties te bespreken. Mensen denken dat alle ‘Kunstmatige Intelligentie’, ‘Machine Learning’ en ‘Deep Learning’ hetzelfde zijn. Maar dat is verkeerd! Laten we even wat duidelijkheid brengen over dit topic:
Kunstmatige intelligentie Kunstmatige intelligentie is het bredere concept van machines/systemen die taken slimmer kunnen uitvoeren. Het omvat alles waardoor computers als mensen kunnen denken en doen.


Machine Learning
Machine Learning is een vorm van AI en is gebaseerd op het idee dat machines/systemen toegang moeten krijgen tot data en vanuit deze data zelf te leren en te verkennen. Het is het herkennen van patronen uit grote data sets.
Deep Learning
Deep Learning is een vorm van Machine Learning waarbij vergelijkbare algoritmen worden gebruikt om Deep Neural Networks te trainen om een betere nauwkeurigheid te bereiken voor de meer complexe projecten.

7 Stappen van Machine Learning
Het Machine Learning proces omvat het bouwen van een voorspellend model dat kan worden gebruikt om een oplossing voor een probleemstelling te vinden. Laten we aannemen dat je een probleem hebt dat moet worden opgelost met behulp van Machine Learning.
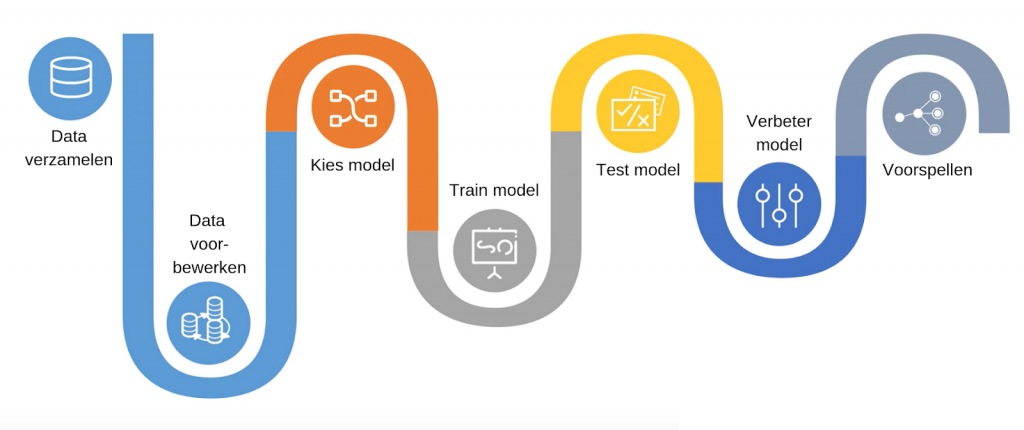
Figuur 3: 7 stappen van machine learning
Machine Learning proces stappen
Stap 1: Begin met het verzamelen van gegevens
Machine learning vereist veel data uit het verleden. Het is essentieel om voldoende historische data te hebben. Stel jezelf vragen zoals: Welke soort data is nodig om dit probleem op te lossen? Is deze data beschikbaar? Hoe kan ik deze data verkrijgen?
Stap 2: Bewerk de data omdat veel ervan niet direct bruikbaar zal zijn.
Je zult vaak inconsistenties tegenkomen in de datasets, zoals ontbrekende waarden, redundante variabelen, dubbele waarden, enz. Het is cruciaal om deze inconsistenties te verwijderen, aangezien ze kunnen leiden tot foutieve berekeningen en voorspellingen.
Stap 3: Kies een model en algoritme.
Welk soort algoritme en welk specifiek model binnen dat algoritme ga je gebruiken? Het juiste algoritme kiezen hangt af van het type probleem dat je probeert op te lossen, de dataset en de complexiteit van het probleem. In de komende secties zullen verschillende soorten problemen worden besproken die met machine learning kunnen worden opgelost.
Stap 4: Train het gekozen model.
Gebruik de trainingsdataset om het model te trainen, zodat het van een blanco model wordt omgezet naar een getraind model.
Stap 5: Test het model om ervoor te zorgen dat het correct voorspelt!
Nadat het model is getraind, is het tijd om het te testen. De testdataset wordt gebruikt om de efficiëntie van het model te controleren en hoe nauwkeurig het voorspellingen kan doen.
Stap 6: Verbeter het model op basis van de nauwkeurigheid.
Na het berekenen van de nauwkeurigheid kunnen verdere verbeteringen worden doorgevoerd. Technieken zoals parameter tuning en cross-validatie kunnen worden gebruikt om de prestaties van het model te verbeteren.
Stap 7: Gebruik het geëvalueerde en verbeterde model om voorspellingen te doen.
Uiteindelijk wordt het model ingezet om voorspellingen te doen. De output kan een categorische variabele zijn (bijvoorbeeld waar of onwaar) of een continue hoeveelheid (bijvoorbeeld de voorspelde waarde van een aandeel).
Dus dat was het hele machine-leerproces. Nu is het tijd om te leren over de verschillende manieren waarop Machines kunnen leren.
Benieuwd hoe u zich kunt onderscheiden van de concurrentie door het implementeren van Artificial Intelligence (Kunstmatige Intelligentie, KI) voor uw organisatie? Download hier het AI-stappenplan!
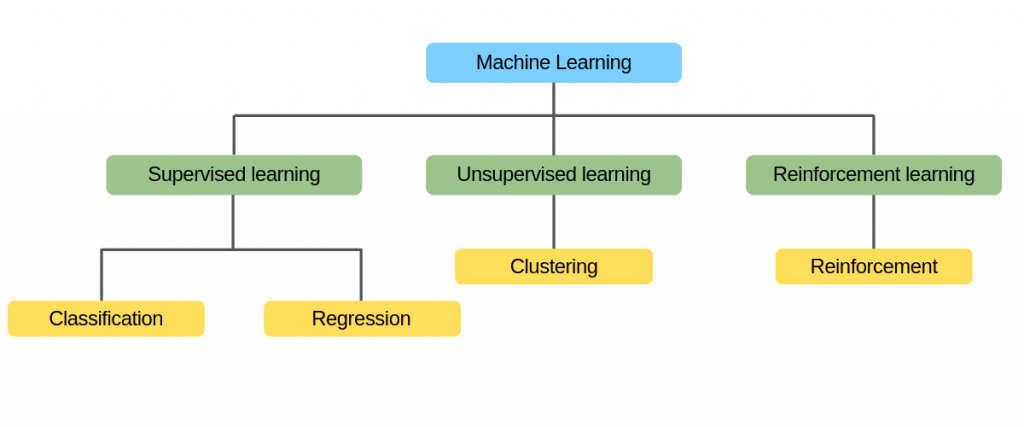
Machine Learning Leer-methoden
Een machine kan leren een probleem op te lossen door één van de volgende drie benaderingen te volgen. Dit zijn de manieren waarop een machine kan leren:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
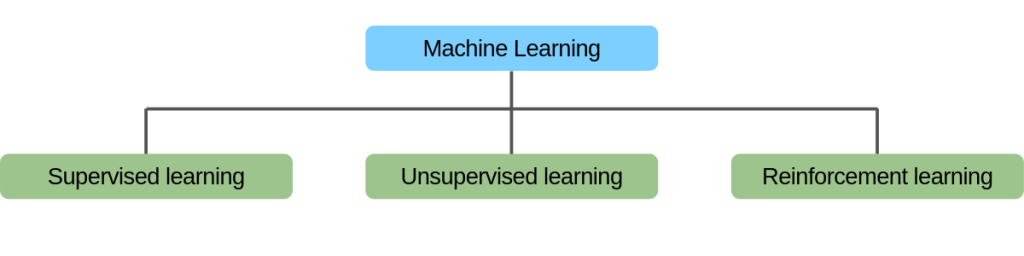
Figuur 4: 3 manieren van leren
Supervised Learning
Supervised Learning is een techniek waarbij we de machine leren of training met behulp van data die goed is gelabeld. Het wordt gebruikt wanneer je een specifieke doelwaarde hebt die je wilt voorspellen. Het doel kan categorisch zijn en twee of meer mogelijke uitkomsten hebben (classificatie). Of het doel kan een waarde zijn die kan worden gemeten. En dat is waar we regressie gebruiken → Gelabelde informatie.
Unsupervised Learning
Unsupervised Learning omvat training door niet-gelabelde data te gebruiken en het model zonder begeleiding op die data te laten reageren. Je hebt dus de data, maar geen gelabelde informatie. Dus dat is waar we associatie en clustering gebruiken om de gegevens die we ontvangen te analyseren.
Reinforcement Learning
Reinforcement Learning is een onderdeel van Machine Learning waarbij de machine/het systeem in een omgeving wordt geplaatst en het zelf leert hoe zich in deze omgeving te gedragen door te observeren en bepaalde acties uit te voeren die resulteren in een bepaalde uitkomst.
Type problemen in Machine Learning
Laten we zeggen dat er een probleem optreedt in jouw bedrijf en je wilt dit probleem oplossen met Machine Learning. Hoe ga je nu beslissen met het ‘opdelen’ van dit probleem, zodat je precies weet welke machine-model en algoritme je moet gebruiken om het probleem op te lossen.
Wanneer er een probleem is, kan je dat probleem indelen in één van de volgende 4 categorieën:
Vraag 1: Is dit A of B? → Classification-algorithm
Het kan dus zijn dat je probleem is opgelost door de vraag te kunnen beantwoorden: Is dit A of B. Zoals in je een probleem hebt, waar het antwoord op de vraag: ‘is dit een apple of een banaan’, de oplossing kan zijn. Wanneer je dit soort problemen hebt gebruik je een classificatie-algoritme (classification).
Vraag 2: Is dit raar? → Clustering Algorithm (Density-Based)
Wanneer je een probleem op kan lossen door de ‘anomaly’ of ‘vreemde vertoningen’ te bepalen, gebruik je deze vorm van een clustering algoritme. Hierbij analyseer je patronen en filter je de vreemde vertoningen / situaties er tussen uit.
Vraag 3: Hoeveel? → Regression Algorithms
Je gebruikt dit algoritme als je een bepaalde numerieke waarden wilt achterhalen. Bijvoorbeeld hoeveel uur je moet inzetten om een bepaald soort project af te ronden. Wanneer je te maken hebt met getallen, pas je dus het regression algorithm toe.
Vraag 4: Hoe is dit georganiseerd? → Clustering Algorithm
Wanneer je dit soort vragen hebt, gebruikt je clustering-algoritmen. Hier probeer je in feite te achterhalen wat de structuur is achter bepaalde data sets. Wanneer je de structuur probeert te achterhalen, gebruik je dus cluster algoritmen.
Vraag 5: Wat moet ik nu doen? → Reinforcement Algorithm
Wanneer een beslissing moet worden genomen, worden algoritmen voor reinforcement learning/algorithm gebruikt.
Figuur 5: Machine learning algoritmen
Elk probleem dat je tegenkomt, kan worden onderverdeeld in de bovenstaande 4 categorieën. Het kan niet verder gaan dan deze 4 categorieën. Dus we hebben nu de verschillende soorten problemen behandeld, laten we eens kijken naar wat voorbeelden:
- Regression: Bij dit soort problemen is de ‘output’ een continue hoeveelheid (continuous quantity). Dus als je bijvoorbeeld de snelheid van een auto wilt voorspellen, gezien de afstand, is dit een ‘regression-probleem’. Regression problemen kunnen worden opgelost met behulp van Supervised Learning algoritmen zoals Linear Regression (later in dit artikelen behandelen we de verschillende algoritmen).
- Classification: Bij dit type probleem, is de ‘output’ een categorische waarde. Het classificeren van e-mails in twee klassen, spam en geen-spam is een ‘classification-probleem’. Classification problemen kunnen worden opgelost met behulp van Supervised Learning algoritmen zoals Support Vector Machines, Naive Bayes, Logistic Regression, K-Nearest Neighbors en meer. Later in dit artikel behandelen we de top 5 meest gebruikte algoritmen in Machine Learning.
- Clustering: Dit type probleem houdt in dat de ‘input’ in twee of meer clusters wordt ingedeeld op basis van gelijkenissen. Zo kunnen kijkers in vergelijkbare groepen worden gebundeld op basis van hun interesses, leeftijd, geografie, enz. Clustering problemen kunnen worden opgelost met behulp van Unsupervised Learning algoritmen zoals K-Means Clustering.
Dus, we hebben gezien dat je alle problemen in 4 categorieën kunt verdelen. Bij iedere categorie hoort een bepaalde algoritme. In het volgende deel gaan we de top 5 algoritmen gebruikt voor Machine Learning behandelen.
Machine Learning Algoritmen
Er zijn er veel verschillende algoritmen voor elk van de soorten problemen (regression, classification en clustering). In dit deel gaan we de meest populaire algoritmen bespreken. Hier de 5 meest gebruikte machine learning-algoritmen op een rij:
- Linear Regression
- Logistic Regression
- Decision Tree & Random Forest
- Naive Bayes
- kNN
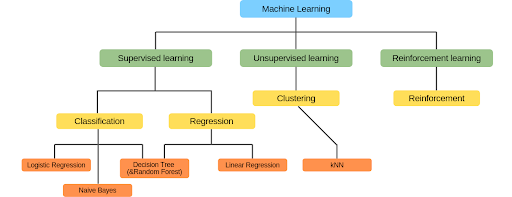
Figuur 6: Machine learning algoritmen
Algoritme 1: Linear Regression
- Linear Regression wordt gebruikt om reële waarden (kosten van huizen, aantal oproepen, totale verkoop enz.) te schatten op basis van continue variabelen. Met een lineaire modelbenadering leggen we een relatie tussen één of meer onafhankelijke variabelen (predictors) aangeduid als X en afhankelijke variabele (target) aangeduid als Y – door de best passende lijn. De best passende lijn staat bekend als de ‘regression-line’ en wordt voorgesteld door een lineaire vergelijking: Y = aX + b.
In deze vergelijking:
- Y = Afhankelijke variabele
- a = Slope
- X = Onafhankelijke variabele
- b = Intercept
Deze coëfficiënten a en b zijn afgeleid op basis van het minimaliseren van de ‘som van het kwadraat verschil’ van de afstand tussen gegevenspunten en de ‘regression-line’
Hier een voorbeeld van ‘niet de best passende lijn’:
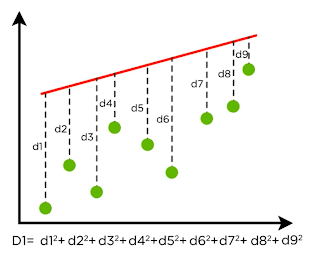
Figuur 7: Regression line – geen passende lijn
Hier een voorbeeld van ‘de best passende regression-line’, waar de lijn de laagste waarde van ‘D’ heeft:
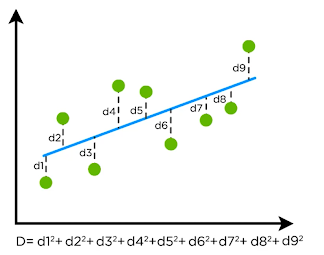
Figuur 8: Regression line – passende lijn
Samenvattend: bij ‘linear regression’ gaat het erom de best passende lijn te vinden. De best passende-lijn (best fit-line) kan worden gevonden door de afstand tussen alle datapunten en de afstand tot de ‘regression line’ te minimaliseren. Manieren om deze afstand te minimaliseren zijn som van kwadraten fouten, som van absolute fouten etc.
Algoritme 2: Logistic Regression
- Laten we het volgende algoritme eens bekijken. Hoewel de naam ‘regression’ bevat, wil ik niet dat je in de war raakt! Dit algoritme wordt NIET gebruikt voor regression, maar voor classification. Het wordt gebruikt om discrete / categorische waarden (binaire waarden zoals 0/1, ja / nee, waar / onwaar) te schatten op basis van een dataset van onafhankelijke variabele(n).
Simpel gezegd, het voorspelt de waarschijnlijkheid van een gebeurtenis door data in te passen in een logit-function. Omdat het de waarschijnlijkheid voorspelt, liggen de output waarden tussen 0 en 1.
Laten we dit nogmaals proberen te begrijpen aan de hand van een eenvoudig voorbeeld.
Stel dat je wilt ontdekken of iemand zijn creditcard betaling in gebreke blijft. Dan zijn er slechts 2 scenario’s: Iemand betaalt de creditcard wel, of niet. Stel je nu voor dat je een breed scala aan data hebt: Creditcard gebruikers, creditcardtransacties, maandelijks creditcard saldo en jaarinkomen.
De uitkomst van deze zou er ongeveer zo uitzien: Als je 100 gebruikers hebt, zal 70% van de mensen hun creditcardschuld terugbetalen en 30% zal in gebreke blijven. Dit is wat Logistic Regression je kan bieden.
Wiskundig gezien, worden de log-kansen van de uitkomst gemodelleerd als een lineaire combinatie van de voorspellende variabelen.
Vergelijking: odds = p / (1-p) = waarschijnlijkheid van gebeurtenis optreden / waarschijnlijkheid van niet gebeurtenis voorkomen $$ ln (odds) = ln (p / (1-p)) logit (p) = ln (p / (1-p)) = b0 + b1X1 + b2X2 + b3X3 …. $$
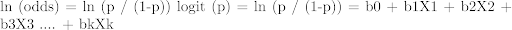
Hierboven is p de waarschijnlijkheid van de aanwezigheid van het kenmerk van interesse. Het kiest parameters die de waarschijnlijkheid van het waarnemen van de steekproef waarden maximaliseren in plaats van die de som van kwadraten fouten minimaliseren (zoals bij gewone regressie).
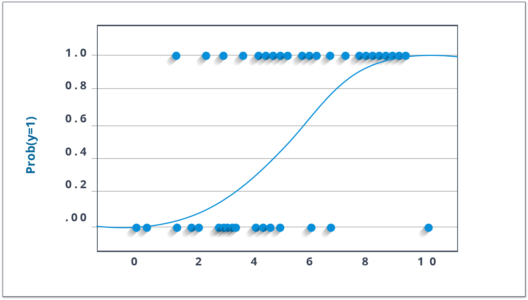
Figuur 9: Logistic Regression
Algoritme 3: Decision Tree (& Random Forest)
Het volgende algoritme is de ‘Decision Tree’ en ‘Random Forest’. Het zijn twee verschillende algoritmen die samen worden gepakt omdat ze nauw met elkaar samenhangen. We zullen het kleine verschil later bespreken.
Decision Tree is een ‘boom’ waarin elke knoop een kenmerk (attribute) vertegenwoordigt, elke link (branch) een beslissing vertegenwoordigt en ieder blad een uitkomst (categorische of continue waarde) vertegenwoordigt. In tegenstelling tot Logistic Regression, die alleen wordt gebruikt voor binaire classificatie, kan de Decision Tree zowel voor Classification als Regression worden gebruikt (vooral populair voor classification), en het werkt met zowel categorische als continue afhankelijke variabelen.
Laten we een voorbeeld nemen: Een persoon ontvangt een baanaanbod en hij/zij moet beslissen of hij/zij dit bod accepteert. Dan ziet de Decision Tree er als volgt uit:
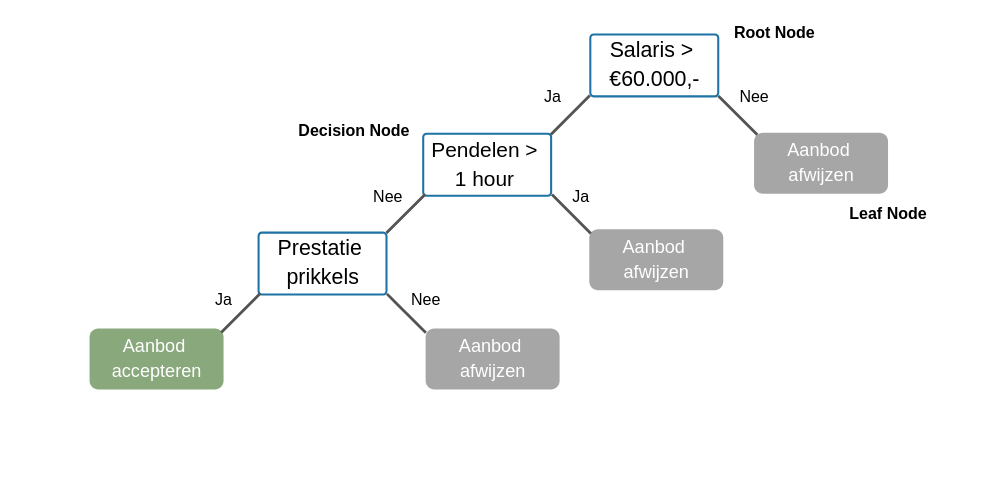
Figuur 10: Decision tree (& random forest)
Het knooppunt waar de boom begint, staat bekend als de ‘Root Node’ en de andere knooppunten zijn ‘Decision Nodes/Internal Nodes’. De uitkomst van de Decision Nodes zijn de ‘Leaf-/Terminal Nodes’.
Stel dat we deze boom moeten gebruiken om erachter te komen of deze persoon de baan moet accepteren of niet, kunnen we dat doen door de vragen na te lopen. Zoals het bovenstaande voorbeeld is het nog steeds een binaire classificatie (weigeren of accepteren), echter worden de groepen onder verschillende redenen verdeeld. Dus je hebt 3 groepen ‘Weigeren’, maar is die groep verdeeld onder 3 verschillende redenen.
Als je uiteindelijk de prestaties van de Decision Tree wilt verbeteren, dan kan je gebruik maken van het algoritme ‘Random Forest’. Wanneer je Random Forest gebruikt, gebruikt je niet één boom, maar meerdere.
Dus je gebruikt meerdere bomen en classificeert iedere observatie, waardoor de nauwkeurigheid wordt verbeterd.
Algoritme 4: Naive Bayes
Dit is een classificatie techniek gebaseerd op de stelling van Bayes met een veronderstelling van onafhankelijkheid tussen ‘predictors’. Simpel gezegd, gaat een Naive Bayes-classificatie ervan uit dat de aanwezigheid van een bepaald kenmerk in een klasse geen verband houdt met de aanwezigheid van een ander kenmerk.
Toepassing
Een vrucht kan bijvoorbeeld als een appel worden beschouwd als deze rood, rond en ongeveer 6 cm in diameter is. Zelfs als deze kenmerken van elkaar afhankelijk zijn of van het bestaan van de andere kenmerken, zou een Naive Bayes-classificeerder al deze eigenschappen overwegen om onafhankelijk bij te dragen aan de waarschijnlijkheid dat deze vrucht een appel is.
Stelling van Bayes in Naive Bayes
Naive Bayes model is eenvoudig te bouwen en bijzonder nuttig voor zeer grote data sets. Naast eenvoud is het bekend dat Naive Bayes zelfs zeer geavanceerde classificatiemethoden overtreft.
De stelling van Bayes biedt een manier om de waarschijnlijkheid P (c | x) te berekenen uit P (c), P (x) en P (x | c). Bekijk de onderstaande vergelijking:

- P( c|x ) is de waarschijnlijkheid van een klasse (target) gegeven voorspeller/predictor (attribute).
- P( c ) is de eerdere waarschijnlijkheid van klasse.
- P( x|c ) is de waarschijnlijkheid die de waarschijnlijkheid is van een klasse met voorspeller/predictor.
- P( x ) is de eerdere waarschijnlijkheid van voorspeller/predictor.
Voorbeeld
Laten we het proberen te begrijpen aan de hand van een voorbeeld. Hieronder hebben we een trainings dataset van het weer en de bijbehorende doelvariabele ‘Play’. Nu moeten we classificeren of de spelers wel of niet zullen spelen op basis van de weersomstandigheden. Laten we de onderstaande stappen volgen om het uit te voeren:
Stap 1: Converteer de dataset naar de frequentie tabel.
Stap 2: Maak een Likelihood-tabel door de kansen te vinden zoals Overcast waarschijnlijkheid = 0,29 en de waarschijnlijkheid van spelen = 0,64.
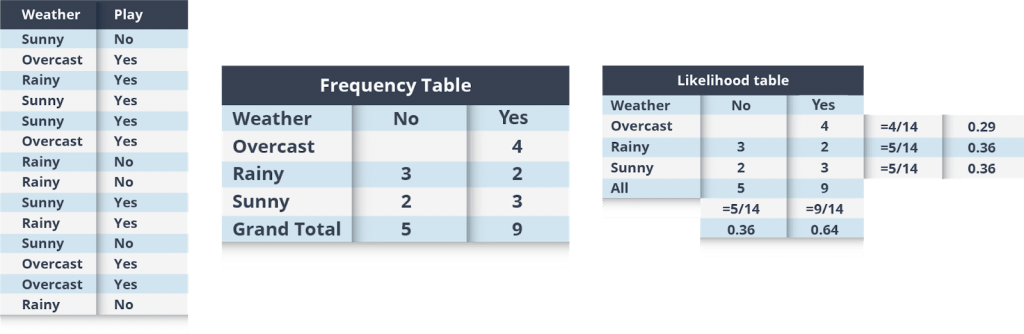
Figuur 11: Naive bayes data
We kunnen het oplossen met behulp van de hierboven besproke methode, dus P (Yes | Zonnig) = (Zonnig | Ja) * P (Yes) / P (Zonnig)
Hier hebben we P (Zonnig | Ja) = 3/9 = 0,33, P(Zonnig) = 5/14 = 0,36, P (Ja) = 9/14 = 0,64.
Nu is P (Ja | Zonnig) = 0,33 * 0,64 / 0,36 = 0,60, wat een grotere kans heeft.
Naive Bayes gebruikt een vergelijkbare methode om de waarschijnlijkheid van verschillende klassen te voorspellen op basis van verschillende attributen. Dit algoritme wordt meestal gebruikt in tekstclassificatie en bij problemen met meerdere klassen.
Algoritme 5: Nearest Neighbors
K Nearest Neighbors wordt gebruikt voor zowel classification- als regression problemen. Het wordt echter op grotere schaal gebruikt bij classification problemen. KNN is een eenvoudige algoritme dat alle beschikbare cases en nieuwe cases classificeert bij meerderheid van stemmen van K Neighbors. De case die aan de klasse wordt toegewezen, komt het meest voor de dichtstbijzijnde K Neighbors gemeten door een afstandsfunctie.
Deze afstandsfuncties kunnen Euclidean, Manhattan, Minkowski en Hamming afstand zijn. De eerste drie functies worden gebruikt voor de continue functie en de vierde (hamming) voor categorische waarden. Als K = 1, wordt de case toegewezen aan de klasse van de dichtstbijzijnde buur. Soms is het kiezen van K een uitdaging bij het uitvoeren van ‘kNN-modelling’.
Voorbeeld
Laten we er een voorbeeld bij pakken. Je hebt de volgende data: Lengte en gewicht van honden en katten. Je gebruikt de data en classificeert dat een bepaalt gewicht katten zijn- en boven dat gewicht, honden. Zoals je je kunt zien in de onderstaande afbeelding:
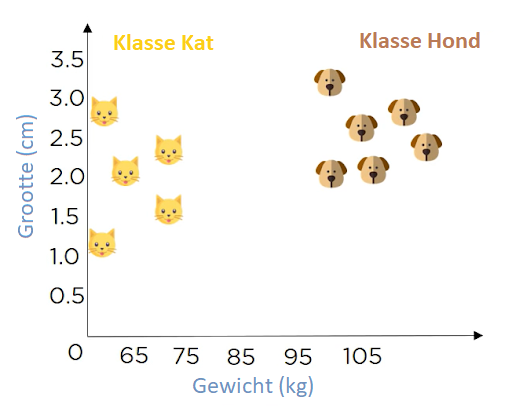
Figuur 12: Nearest neighbors data
Nu heb je een nieuw datapunt en wil je bepalen of het een kat of een hond is…
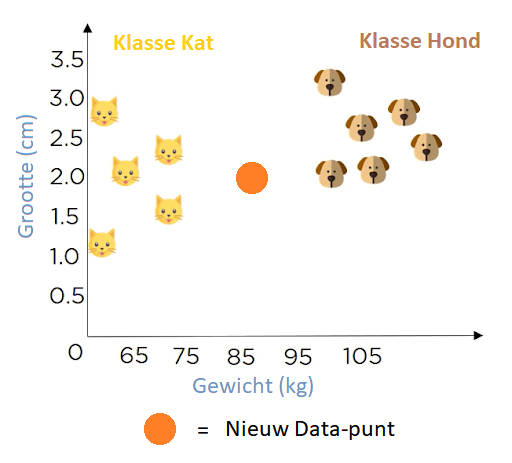
Figure 13: Nearest neighbors data-punt
Dat is waar de waarde K een rol speelt – dus moeten we de waarde van K specificeren. Dus laten we zeggen dat de waarde K = 3. Nu moeten we de 3 gegevenspunten vinden die we al hebben, die het dichtst bij het nieuwe datapunt liggen.
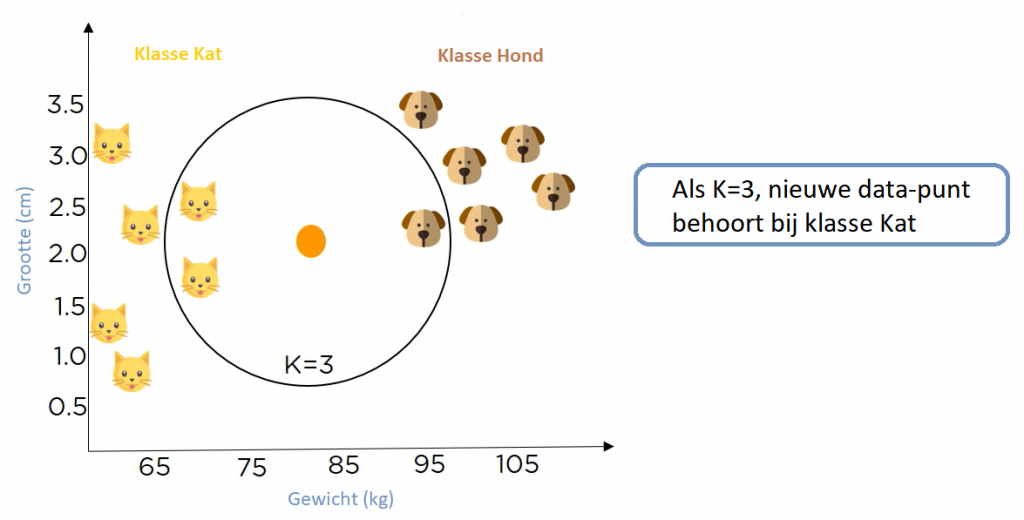
Figuur 14: Nearest neighbors data-punt K=3
Nu zie je dat er in dit bereik meer katten dan honden zijn. Dus als K = 3, dan behoort de nieuwe data punt tot klasse ‘Kat’.
Wat gebeurt er als we vaststellen dat K in wachtrij staat bij 7. Daarom is K = 7, het nieuwe gegevenspunt behoort tot klasse Hond.
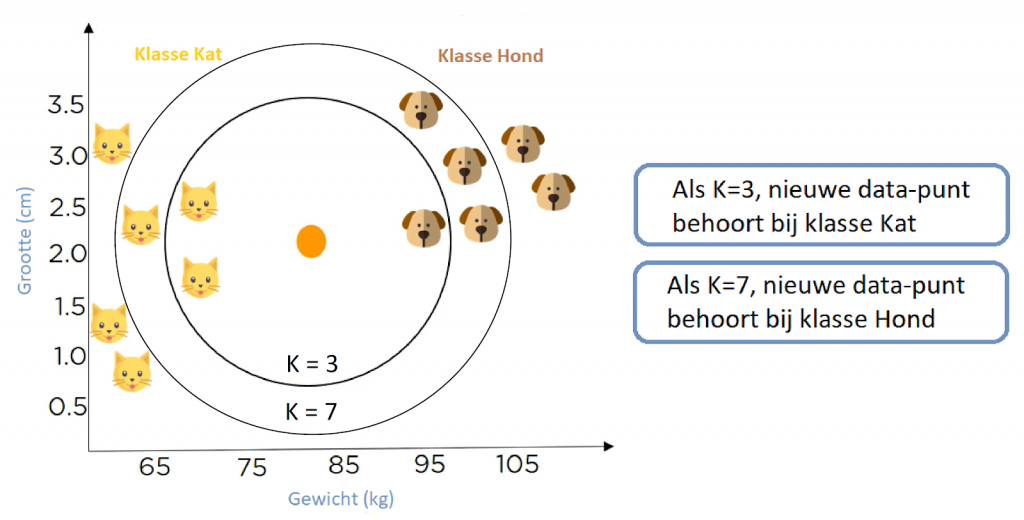
Figuur 15: Nearest neighbors data-punt K=7
Met vallen en opstaan moeten we de juiste waarde van K kunnen vinden en dat gebruiken we. Dat is hoe we het model trainen.
Wat hebben we geleerd?
Machine Learning is een subset van Kunstmatige Intelligentie (AI), waarmee systemen data-gestuurde beslissingen kunnen nemen. Om deze beslissingen te kunnen nemen, moeten we het systeem trainen, en om het systeem te trainen, hebben we data nodig.
Machine Learning leert deze data op 3 verschillende manieren:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
Elke vorm van ‘leren’ bepaalt welke soorten problemen kunnen worden opgelost, verdeeld onder:
- Classification
- Regression
- Clustering
- Reinforcement
Hier is een tabel die het verschil tussen Regression, Classification, Clustering en Reinforcement samenvat:
| Regression | Classification | Clustering |
|---|---|---|
| Supervised Learning | Supervised Learning | Unsupervised Learning |
| Output is een continue hoeveelheid | Output is een categorische hoeveelheid | Wijst data-punten toe aan clusters |
| Hoofddoel is om te voorspellen | Hoofddoel is om de data categorie te berekenen | Hoofddoel is om het groeperen van gelijkwaardige item clustes |
| Bv: Voorspel waarde van aandeel | Bv: Classificeren van emails als spam of geen-spam | Vind alle transacties die frauduleus van aard zijn |
| Algoritme: Linear Regression | Algoritme: Logistic Regression | Algoritme: K-means |
**Reinforcement Algoritmen is hier niet meegenomen. Wat we met Reinforcement kunnen bereiken gaat diep, daarom wordt dat behandelt in een apart artikel.
Ieder type probleem heeft dus een oplossing, en we hebben bekeken welke algoritmen je voor een bepaald probleem kunt gebruiken. Hier zijn nog eens de 5 meest gebruikte algoritmen op een rij:
- Linear Regression
- Logistic Regression
- Decision Tree (& Random Forest)
- Naive Bayes
- k-NN (Nearest Neighbors)Welcome to StackEdit!
Conclusie: waarom machine learning onmisbaar is
Machine learning is een essentiële technologie die bedrijven helpt bij data-analyse, procesoptimalisatie en voorspellingen. Door AI-modellen te trainen met de juiste data, kunnen systemen zelfstandig patronen herkennen en intelligente beslissingen nemen. Dit maakt processen efficiënter, kosten lager en beslissingen nauwkeuriger.
We hebben gezien dat machine learning werkt op drie manieren:
- Supervised learning – AI leert van gelabelde data.
- Unsupervised learning – AI ontdekt zelf patronen in ongestructureerde data.
- Reinforcement learning – AI leert door trial-and-error en beloningen.
Daarnaast hebben we gekeken naar de belangrijkste machine learning-algoritmen en hoe ze worden toegepast in classification, regression en clustering.
Machine learning is niet alleen voor techbedrijven, maar wordt al gebruikt in marketing, gezondheidszorg, transport, finance en logistiek. Bedrijven zoals Netflix en Amazon optimaliseren hun diensten met machine learning, en ook kleinere bedrijven kunnen hiervan profiteren.
“Data is de nieuwe brandstof. Machine learning is de motor die het omzet in waardevolle inzichten.”
🚀 Wil jij machine learning toepassen in jouw bedrijf?
Benieuwd hoe machine learning en AI jouw bedrijf kunnen helpen groeien? Ontdek:
- Welke AI-modellen het beste passen bij jouw sector
- Hoe je machine learning implementeert met een duidelijk stappenplan
- Hoe je fouten voorkomt bij AI-implementatie
👉 Doe de AI-Check!
AI Check
Is jouw bedrijf AI-Ready?